Introducing RALTS (Really Awesome Lexicon and Tag Suggester)
Filed under: Python | SEO | AI
I’ve been learning Python since October 2019 and exploring NLP since the end of last year and they’ve changed my life for the better. As I learn by doing, I’ve decided to show off arguably my greatest creation to do date. I wasn’t sure whether to do it as it’s very niche to me but I’ve taken a step out of my comfort zone.
GitHub link to RALTS repository
Table of contents
- What is RALTS?
- Why did I make it?
- Notes on my coding
- Some definitions
- Tech requirements
- The code
- Who could this benefit?
- Evaluation
- Summary
What is RALTS?
RALTS stands for (Really Awesome Lexicon and Tag Suggester) and it’s a script that extracts entities, topics, and categories from a body of text using the TextRazor API. But what it also does is use NLP classification to analyse that text based on labels pulled from the extracted topics. Confused? I’ll explain those all in more detail later.
There is also a secondary function that has nothing to do with suggesting tags but I’ll explain it here. I have also set up functionality that pulls all my tags from my blogs and randomly joins them together in a Google search query for content ideas. They are inversely weighted so the least used tags appear more frequently in the randomised search queries.
Examples:
- https://google.com/search?q=vhs+black+cinema
- https://google.com/search?q=cuba+snow
- https://google.com/search?q=nike+poetry
- https://google.com/search?q=night+keith+haring
- https://google.com/search?q=australia+dogs
In terms of the name, I chose RALTS because all the Sesame Street references were taken and I’m a Pokémon fan. It’s a backronym but it works for me.
Why did I make it?
tl;dr: it aids my blogging process.
I love anything to do with taxonomies, ontologies, and classification. I’m a tagger and a labeler. There are limits to what and how I label in a social and metaphysical sense but for my blogs, I love the process. It helps my information retrieval and it ties so well into SEO (which is my profession in case you missed it).
Fundamentally, I wanted a script to tell me what tags to use for my blogs if I couldn’t think of any or had retrospectively missed anything. By extracting entities and topics, I can cross reference it with existing tags or spot any new ones that make sense or keep cropping up.
Notes on my coding
Before I dive into the code, I want to make something clear: I’ve only been coding in Python for just under 2.5 years. I’ve done all of this in my own time with no formal training and following a Udemy course I still haven’t finished. You’ll likely see some inefficient or unpythonic code. If you do, feel free to shout up as that will help me improve. But please: only constructive feedback. There are way too many videos online calling people out for “stupid code” and I find it demeaning and gatekeep-y (technical term).
I also want to give credit to Joe Davison whose data plot code I used from his zero shot demo. He wrote a great piece on zero shot learning which you should read if you’re interested.
There’s also a live zero shot classification demo you can try that shows the code I copied in action.
If I’ve taken anything that belongs to anyone whom I’ve forgotten to credit or if you’d prefer I remove it, please let me know and accept my sincerest apologies.
Some definitions
So, about that original explanation. Let’s look at some definitions:
-
Entities - Real-world objects, such as people, organisations, locations, products, that can be denoted with a proper name. They can be abstract or have a physical existence. Examples of named entities include: Python, London, David Beckham, Nelson Mandela, Manchester United, The Simpsons, cooking.
-
Topics - These are broader terms that can describe wider ranges of ideas. Examples of topics include: American sitcoms, British footballers, programming languages, capital cities, world leaders, television series. Sometimes an entity can be a topic. In the specific context of the Text Razor API, a topic is more specific than a category and TextRazor has “an automatic understanding of hundreds of thousands of different topics at different levels of abstraction”.
-
Categories - The term “categories” is sometimes used interchangably with topics but in this context, a category is a broader term with which an entity and/or topic can fall under. Examples of categories include: arts, culture and entertainment > animation; health > hospital and clinic; economy, business and finance > media > advertising
-
Text classification - the task of assigning a document or text to one or more classes, categories, or labels. In NLP, this can be done manually or programmatically. The aim of the script is to do this with the help of the extracted topics and a machine learning language model.
-
Labels - Forms of annotation that classify what a text is about. They’re basically like tags.
Tech requirements
These are the following Python packages used in the script:
streamlit>=1.0.0
pandas>=1.2.3
transformers>=4.12.3
requests>=2.25.1
bs4>=0.0.1
plotly>=5.4.0
numpy>=1.18.0
textrazor==1.4.0
tensorflow>=2.7.0
Streamlit for the UI, pandas for data manipulation, Transformers for the language model, requests and BeautifulSoup for web scraping, plotly and NumPy for data viz, TextRazor for the entities and such, and TensorFlow for the language model.
Regarding TensorFlow, the language model I’m using is called DistilBart-MNLI and instructions can be found on the Hugging Face link about how to download, fine-tune, deploy, and use in Transformers via Python.
The code
The code is split into different parts:
1. TextRazor API key and client details
# TextRazor details
textrazor.api_key = API_KEY
client = textrazor.TextRazor(extractors=["entities", "topics"])
client.set_classifiers(["textrazor_newscodes"])
We set the API key (which you can generate with a free account on the TextRazor website) and tell the client to use the entities and topics extractors. We also set the classifiers to textrazor_newscodes. Find out more on TextRazor’s Classification page.
2. Function for loading the language model via a pipeline using zero shot classification, the classification process, plotting the results, and web scraping
# Load model
@st.cache(allow_output_mutation=True)
def load_model():
return pipeline("zero-shot-classification",
model='valhalla/distilbart-mnli-12-9',
multi_label=True)
# Classification function
def classify(sequences, candidate_labels):
output_results = load_model()(sequences=sequences,
candidate_labels=candidate_labels)
return output_results['labels'], output_results['scores']
# Graph plot function
def plot_result(top_topics, scores):
top_topics = np.array(top_topics)
scores = np.array(scores)
scores *= 100
fig = px.bar(x=scores,
y=top_topics,
orientation='h',
labels={'x': 'Confidence', 'y': 'Label'},
text=scores,
range_x=(0,115),
title='Top Predictions',
color=np.linspace(0,1,len(scores)),
color_continuous_scale='GnBu')
fig.update(layout_coloraxis_showscale=False)
fig.update_traces(texttemplate='%{text:0.1f}%',
textposition='outside')
st.plotly_chart(fig)
def req(url):
resp = requests.get(url)
soup = BeautifulSoup(resp.content, 'html.parser')
if soup.find("div", id="comments") or soup.find("div", id="secondary"):
remove_comments = soup.find("div", id="comments")
remove_comments.extract()
remove_secondary = soup.find("div", id="secondary")
remove_secondary.extract()
ext_t = [t.text for t in soup.find_all(['h1', 'p'])]
paragraphs = ' '.join(ext_t)
return paragraphs
else:
ext_t = [t.text for t in soup.find_all(['h1', 'p'])]
paragraphs = ' '.join(ext_t)
return paragraphs
# Main function
def main():
with st.spinner('Classifying...'):
global txt
df_classify_topic = pd.DataFrame(topics_dict)
df_classify_topic = df_classify_topic.sort_values(
by='Relevance Score', ascending=False)
classify_topic_score = list(
df_classify_topic['Topic'][:10])
if input_type == 'Text':
top_topics, scores = classify(
txt, classify_topic_score)
elif input_type == 'URL':
txt = req(url)
top_topics, scores = classify(
txt, classify_topic_score)
elif input_type == 'Multiple URLs':
txt = ' '.join(all_txt)
top_topics, scores = classify(
txt, classify_topic_score)
plot_result(top_topics[::-1][-10:], scores[::-1][-10:])
There’s a lot here so I’ll break it down further.
The first function loads the distilbart model for this task and uses zero-shot classification to determine classification. I have also set a cache so it doesn’t reload every time, which saves loading time and CPU/GPU resources.
The second function is for the actual classification. It loads the model, and generates output results containing the labels and the relevance scores for each. Which labels we use are determined later.
The third function plots a horizontal bar chart of the top 10 labels alongside their scores. This allows us to visualise the best classification labels of the analysed text.
Here’s how the model classified this blog post:
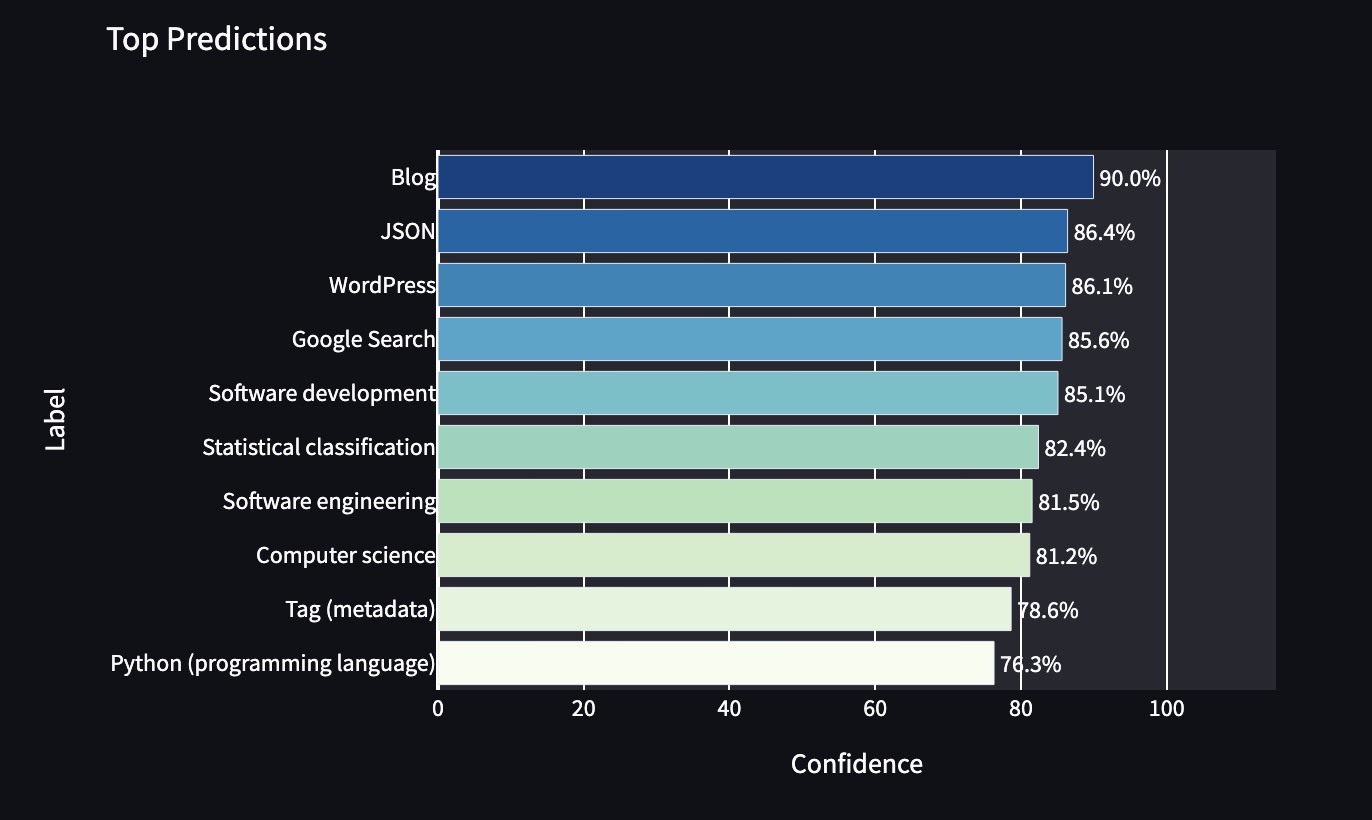
The fourth function is the URL scraper. It takes a URL, extracts the HTML, ignores any comments sections or text found in sidebars (thanks to Jess for the help with that) and finally filters the remaining text down to just the H1 title and text found in p tags, ready for analysis.
The fifth and final function brings everything together. It creates dataframes out of the found entities and topics and orders them by relevance score for ease.
3. Dictionaries
kw_dict = {
'Keyword': []
}
ent_dict = {
'Keyword': [],
'Relevance Score': [],
'Existing Tag': []
}
topics_dict = {
'Topic': [],
'Relevance Score': [],
'Existing Tag': []
}
categories_dict = {
'Category': [],
'Relevance Score': []
}
tags = {
'Tag': [],
'ID': [],
'Count': []
}
Arguably the easiest part, just setting the dictionaries for our entity outputs as well as the tags for the additional part of our script which is up next.
4. Establishing the blogs to cross-reference my entities with their respective tag lists
# Blog list
blogs = ['sampleface.co.uk',
'cultrface.co.uk',
'logicface.co.uk',
'playrface.co.uk',
'distantarcade.co.uk']
# Empty lists for existing tags and text from multiple URLs
existing_tags = []
all_txt = []
# Upper limits for tag page range
upper_limits = {
'sampleface.co.uk': 4,
'cultrface.co.uk': 4,
'logicface.co.uk': 2,
'playrface.co.uk': 2,
'distantarcade.co.uk': 2,
'ld89.org': 1
}
Here, we introduce the blogs for our content ideas generator using tags from my blogs. I made a list of all 5 blogs to choose, created empty lists to add existing tags and set upper limits for the tag page ranges.
The tag data comes from WordPress’s REST API which lists various elements of a WordPress blog such as tags, categories, posts, and media. For the tags, I can pull data at 100 tags per page but when I need to run the for-loop to pull what I need, I need to set an upper limit (eg. if I have 350 tags, the range would be from 0 to 4).
Also, I have to set this upper limit manually as I have no way of automating it (but if such a way exists, please let me know!)
5. The Streamlit UI stuff
# Streamlit stuff
st.sidebar.title('Tag suggester')
input_type = st.sidebar.radio(
'Select your input type',
['Text', 'URL', 'Multiple URLs'])
update_tags = st.sidebar.button('↻ Refresh tags')
tag_ideas = st.sidebar.button('Load tag ideas')
# Determines input types
st.title('Welcome to RALTS (Really Awesome Lexicon and Tag Suggester)!')
st.write('This script can analyse any body of text or URL to find extract keywords, topics, and categories using NLP (natural language processing).')
if input_type == 'Text':
txt = st.text_area('Enter text to be analysed...')
txt = txt.replace('\n', ' ').replace('"', '').replace('“','').replace('”', '').replace('‘','').replace('’', '').replace("'s", '').replace(",", '')
st.write(len(txt))
elif input_type == 'URL':
url = st.text_input('Enter URL')
elif input_type == 'Multiple URLs':
multi_url = st.text_area('Enter keywords, 1 per line')
This displays all the inputs and radio buttons needed to pick the right functionality.
6. Functions for updating my tag lists via WordPress’s REST API
def update_all_tags():
with st.spinner('Reloading tags...'):
for blog in blogs:
# Get tag data
for pg in range(1, upper_limits[blog]+1):
tag_url = f'https://{blog}/wp-json/wp/v2/tags?per_page=100&page={pg}'
r_tag = requests.get(tag_url)
api_tags = r_tag.json()
for n in range(0,len(api_tags)):
tags['Tag'].append(api_tags[n]['name'])
tags['ID'].append(api_tags[n]['id'])
tags['Count'].append(api_tags[n]['count'])
with open(f"{blog}.json", "w") as outfile:
json.dump(tags, outfile)
tags['Tag'] = []
tags['ID'] = []
tags['Count'] = []
list_of_blogs = st.radio("Select the corresponding blog", blogs)
# Load JSON files
with open(f'{list_of_blogs}.json', 'rb') as f:
blog_json = json.load(f)
x = blog_json['Tag']
for n in x:
existing_tags.append(n)
submit = st.button('Submit')
if update_tags:
update_all_tags()
There are two functions linked to the tag data. First is a function that pulls the tag name, tag ID, and how many posts have been assigned to that tag and adds them to a dictionary. This is then saved to a JSON file for offline use. Doing this avoids making multiple API calls since, theoretically, the tag data won’t change that frequently. But when it does change, you can refresh the JSON files. These were formerly pickle files but due to the poor security, I spent a few hours switching this code out. I still love pickles though.
From there, we can also read those files and add them to our existing_tags list ready for cross referencing against the extracted entities we find.
7. The random functions for content ideas
# Tag ideas functions
def sf_words():
with open("sampleface.co.uk.json") as sf_json_file:
sf = json.load(sf_json_file)
sf_words_lists = sf['Tag']
return sf_words_lists
def cultr_words():
with open("cultrface.co.uk.json") as cf_json_file:
cf = json.load(cf_json_file)
cf_words_lists = cf['Tag']
return cf_words_lists
def logic_words():
with open("logicface.co.uk.json") as lf_json_file:
lf = json.load(lf_json_file)
lf_words_lists = lf['Tag']
return lf_words_lists
def playr_words():
with open("playrface.co.uk.json") as pf_json_file:
pf = json.load(pf_json_file)
pf_words_lists = pf['Tag']
return pf_words_lists
def da_words():
with open("distantarcade.co.uk.json") as da_json_file:
da = json.load(da_json_file)
da_words_lists = da['Tag']
return da_words_lists
all_words_list = [sf_words(), cultr_words(), logic_words(), playr_words(), da_words()]
def sampleface():
st.header('Sampleface ideas')
for sample in range(5):
with open("sampleface.co.uk.json") as sf_json_file:
sf = json.load(sf_json_file)
sf_words_count_lists = sf['Count']
try:
x = [n/(n+1) for n in sf_words_count_lists]
except ZeroDivisionError:
continue
# sf_choices = random.choices(sf_words_count_lists, weights=(1/n), k=2)
sample = random.choices(sf_words(), x, k=2)
st.write('https://google.com/search?q=' + '+'.join(sample).lower().replace(' ', '+').replace('&', ''))
def cultrface():
st.header('Cultrface ideas')
for sample in range(5):
with open("cultrface.co.uk.json") as cf_json_file:
cf = json.load(cf_json_file)
cf_words_count_lists = cf['Count']
try:
x = [n/(n+1) for n in cf_words_count_lists]
except ZeroDivisionError:
continue
# sf_choices = random.choices(sf_words_count_lists, weights=(1/n), k=2)
sample = random.choices(cultr_words(), x, k=2)
st.write('https://google.com/search?q=' + '+'.join(sample).lower().replace(' ', '+').replace('&', ''))
def logicface():
st.header('LOGiCFACE ideas')
for sample in range(5):
with open("logicface.co.uk.json") as lf_json_file:
lf = json.load(lf_json_file)
lf_words_count_lists = lf['Count']
try:
x = [n/(n+1) for n in lf_words_count_lists]
except ZeroDivisionError:
continue
sample = random.choices(logic_words(), x, k=2)
st.write('https://google.com/search?q=' + '+'.join(sample).lower().replace(' ', '+').replace('&', ''))
def playrface():
st.header('Playrface ideas')
for sample in range(5):
with open("playrface.co.uk.json") as pf_json_file:
pf = json.load(pf_json_file)
pf_words_count_lists = pf['Count']
try:
x = [n/(n+1) for n in pf_words_count_lists]
except ZeroDivisionError:
continue
sample = random.choices(playr_words(), x, k=2)
st.write('https://google.com/search?q=' + '+'.join(sample).lower().replace(' ', '+').replace('&', ''))
def distantarcade():
st.header('Distant Arcade ideas')
for sample in range(5):
with open("distantarcade.co.uk.json") as da_json_file:
da = json.load(da_json_file)
da_words_count_lists = da['Count']
try:
x = [n/(n+1) for n in da_words_count_lists]
except ZeroDivisionError:
continue
sample = random.choices(da_words(), x, k=2)
st.write('https://google.com/search?q=' + '+'.join(sample).lower().replace(' ', '+').replace('&', ''))
def all_blogs():
sampleface()
cultrface()
logicface()
playrface()
distantarcade()
I’ll try to summarise this part as it is quite lengthy. Each JSON file is read and the relevant list is pulled containing all the respective blogs’ tags. To generate the Google Search URLs, a for-loop picks out the tags’ counts and generates a new list which can be used for weighting in the random.choices method. Then a series of 2-3 tags are chosen at random, weighted by least used tag = most likely chosen and appended to the Google Search URL.
Finally, they’re all grouped together in a main function ready to be called at the click of a button.
8. The entity, topic, and category functions using the TextRazor API
# Keyword extraction function to analyse with TextRazor
def textrazor_extraction(input_type):
if input_type == 'Text':
global txt
response = client.analyze(txt)
for entity in response.entities():
if entity.relevance_score > 0:
ent_dict['Keyword'].append(entity.id)
ent_dict['Relevance Score'].append(entity.relevance_score)
if entity.id.lower() in existing_tags or entity.id.capitalize() in existing_tags:
ent_dict['Existing Tag'].append(1)
else:
ent_dict['Existing Tag'].append(0)
for topic in response.topics():
if topic.score > 0.6:
topics_dict['Topic'].append(topic.label)
topics_dict['Relevance Score'].append(topic.score)
if topic.label.lower() in existing_tags or topic.label.capitalize() in existing_tags:
topics_dict['Existing Tag'].append(1)
else:
topics_dict['Existing Tag'].append(0)
for category in response.categories():
categories_dict['Category'].append(category.label)
categories_dict['Relevance Score'].append(category.score)
elif input_type == 'URL':
txt = req(url)
response = client.analyze(txt)
for entity in response.entities():
if entity.relevance_score > 0:
ent_dict['Keyword'].append(entity.id)
ent_dict['Relevance Score'].append(entity.relevance_score)
if entity.id.lower() in existing_tags or entity.id.capitalize() in existing_tags:
ent_dict['Existing Tag'].append(1)
else:
ent_dict['Existing Tag'].append(0)
for topic in response.topics():
if topic.score > 0.6:
topics_dict['Topic'].append(topic.label)
topics_dict['Relevance Score'].append(topic.score)
if topic.label.lower() in existing_tags or topic.label.capitalize() in existing_tags:
topics_dict['Existing Tag'].append(1)
else:
topics_dict['Existing Tag'].append(0)
for category in response.categories():
categories_dict['Category'].append(category.label)
categories_dict['Relevance Score'].append(category.score)
elif input_type == 'Multiple URLs':
for u in urls:
txt = req(u)
all_txt.append(txt)
response = client.analyze(txt)
for entity in response.entities():
if entity.relevance_score > 0:
ent_dict['Keyword'].append(entity.id)
ent_dict['Relevance Score'].append(entity.relevance_score)
if entity.id.lower() in existing_tags or entity.id.capitalize() in existing_tags:
ent_dict['Existing Tag'].append(1)
else:
ent_dict['Existing Tag'].append(0)
for topic in response.topics():
if topic.score > 0.6:
topics_dict['Topic'].append(topic.label)
topics_dict['Relevance Score'].append(topic.score)
if topic.label.lower() in existing_tags or topic.label.capitalize() in existing_tags:
topics_dict['Existing Tag'].append(1)
else:
topics_dict['Existing Tag'].append(0)
for category in response.categories():
categories_dict['Category'].append(category.label)
categories_dict['Relevance Score'].append(category.score)
Depending on the input (text, URL, or multiple URLs), this function analyses the text, finds the topics, entities, and categories and adds them to a dictionary. I set a threshold for the relevance score to ignore anything that had a score of 0. I also added a check for matching tags, so if an entity is already in my tag list, it’ll give me a 1 or 0 if not. It’s worth noting that this is inconsistent despite my best efforts so if you see the code and can tell me how to do this better, let me know!
9. The function for displaying that data in DataFrame form
# DataFrames to present above data
def data_viz():
if input_type == 'Text':
# df_kw = pd.DataFrame(kw_dict)
# # grouped_df_kw = df_kw.groupby(['Keyword']).agg({'Relevance Score': ['mean'], 'Existing Tag': ['max']}).round(3)
# # grouped_df_kw = grouped_df_kw.reset_index()
# st.header('Keywords')
# st.dataframe(df_kw)
df_ent = pd.DataFrame(ent_dict)
grouped_df_ent = df_ent.groupby(['Keyword']).agg({'Relevance Score': ['mean'], 'Existing Tag': ['max']}).round(3)
grouped_df_ent = grouped_df_ent.reset_index()
st.header('Entities')
st.dataframe(grouped_df_ent)
df_topic = pd.DataFrame(topics_dict)
grouped_df_topic = df_topic.groupby(['Topic']).agg({'Relevance Score': ['mean'], 'Existing Tag': ['max']}).round(3)
grouped_df_topic = grouped_df_topic.reset_index()
st.header('Topics')
st.dataframe(grouped_df_topic)
df_cat = pd.DataFrame(categories_dict)
grouped_df_cat = df_cat.groupby(['Category']).agg({'Relevance Score': ['mean']}).round(3)
grouped_df_cat = grouped_df_cat.reset_index()
st.header('Categories')
st.dataframe(grouped_df_cat)
elif input_type == 'URL':
df_ent = pd.DataFrame(ent_dict)
grouped_df_ent = df_ent.groupby(['Keyword']).agg({'Relevance Score': ['mean'], 'Existing Tag': ['max']}).round(3)
grouped_df_ent = grouped_df_ent.reset_index()
st.header('Entities')
st.dataframe(grouped_df_ent)
df_topic = pd.DataFrame(topics_dict)
grouped_df_topic = df_topic.groupby(['Topic']).agg({'Relevance Score': ['mean'], 'Existing Tag': ['max']}).round(3)
grouped_df_topic = grouped_df_topic.reset_index()
st.header('Topics')
st.dataframe(grouped_df_topic)
df_cat = pd.DataFrame(categories_dict)
grouped_df_cat = df_cat.groupby(['Category']).agg({'Relevance Score': ['mean']}).round(3)
grouped_df_cat = grouped_df_cat.reset_index()
st.header('Categories')
st.dataframe(grouped_df_cat)
elif input_type == 'Multiple URLs':
df_ent = pd.DataFrame(ent_dict)
grouped_df_ent = df_ent.groupby(['Keyword', 'Existing Tag']).describe().round(3)
grouped_df_ent = grouped_df_ent.reset_index()
st.header('Entities')
st.dataframe(grouped_df_ent)
df_topic = pd.DataFrame(topics_dict)
grouped_df_topic = df_topic.groupby(['Topic', 'Existing Tag']).describe().round(3)
grouped_df_topic = grouped_df_topic.reset_index()
st.header('Topics')
st.dataframe(grouped_df_topic)
df_cat = pd.DataFrame(categories_dict)
grouped_df_cat = df_cat.groupby('Category').describe().round(3)
grouped_df_cat = grouped_df_cat.reset_index()
st.header('Categories')
st.dataframe(grouped_df_cat)
The penultimate function converts those dictionaries into dataframes. The data is aggregated by relevance score (if multiple instances of an entity are found, I get the mean relevance score), and the max value of existing tags (1 or 0). For multiple URLs, I’ve used describe() to give me a full range of statistical data. Most of it is superfluous but it was the best thing I could find to get the data I needed.
Below is a table of the top 5 entities found in this blog post, ordered by relevance score:
| Keyword | Relevance Score | Existing tag |
|---|---|---|
| Website | 0.6620 | 0 |
| Search engine optimization | 0.6460 | 0 |
| Web scraping | 0.6450 | 0 |
| World Wide Website | 0.6440 | 0 |
| HTML | 0.6320 | 0 |
A table of the top 5 topics found in this blog post, ordered by relevance score:
| Topic | Relevance Score | Existing tag |
|---|---|---|
| API | 1.0000 | 0 |
| Blog | 1.0000 | 0 |
| Computer science | 1.0000 | 1 |
| Computing | 1.0000 | 0 |
| Google Search | 1.0000 | 0 |
And a table of the top 5 categories found in this blog post, ordered by relevance score:
| Category | Relevance Score |
|---|---|
| economy, business and finance>computing and information technology | 0.8100 |
| economy, business and finance>computing and information technology>software | 0.7330 |
| arts, culture and entertainment>internet | 0.6020 |
| arts, culture and entertainment>language | 0.5620 |
| science and technology>engineering | 0.5360 |
10. Execution of the all the functions to make it work
# Execute functions
if tag_ideas:
all_blogs()
elif submit and input_type and input_type == 'Text':
textrazor_extraction('Text')
data_viz()
main()
elif submit and input_type == 'URL':
textrazor_extraction('URL')
data_viz()
main()
elif submit and input_type == 'Multiple URLs':
urls = [line for line in multi_url.split("\n")]
textrazor_extraction('Multiple URLs')
data_viz()
Finally, we have all the functions ready to call, depending on whether I’m analysing raw text or URLs.
Who could this benefit?
As I said earlier, I’ve made this mainly for myself and as a way to improve my taxonomies. I made a pledge to write about more Black content and scripts like this keep me in check as I can fill in gaps where content is lacking. It also inspires me to learn new things I never would have found from plain searching or from the blogs I follow (also part of my process which I wrote about a few years ago).
But this kind of script is for any of the following types of people:
- To analyse text for entity relevance
- To find internal linking opportunities, particularly those interested in using LOD (linked open data)
- Content ideas
- To check if your text is aligned how you want it
Evaluation
This Python script is not perfect. It’s rough around the edges and works for my specific use case so for anyone else, they would need to tweak it or potentially rewrite it for their own needs.
One significant change that could be made is with the use of the BART model. This isn’t fine-tuned in anyway so its classification could be improved if you trained the model on specific datasets.
There are also no means of downloading the outputted data. This is a personal preference as I tend to read off the screen and move on but for other use cases, you may want the CSVs. That can be added in.
Summary
I hope this has been insightful for anyone reading. While I’ve been learning Python and it makes sense to me, I appreciate it can feel daunting to take this in without the same knowledge. I rarely have to explain my personal projects and don’t like to say “hey, I made this thing” because who cares (that’s what I say in my head anyway). At the very least, I can say I did a thing and explained why and it will benefit me.